9.2 Spark
Apache Spark é uma ferramenta de processamento paralelo para ciência de dados, engenharia de dados e machine learning, que foi criada em uma pesquisa do Amplab da universidade de Berkeley em 2009 e se tornou open source em 2010 com a publicação do paper:
https://people.csail.mit.edu/matei/papers/2010/hotcloud_spark.pdf
O conceito de RDD (Resilient Distributed Datasets) do Spark foi bastante difundido com o seguinte paper:
https://people.csail.mit.edu/matei/papers/2012/nsdi_spark.pdf
E em 2013 foi incubada pela Apache Software Foundation.
9.2.1 Conceitos
RDD (Resilient Distributed Datasets)
RDDs é uma abstração de uma coleção de dados distribuída que permite a criação de programas para manipular os dados distribuídos. RDDs são coleções imutáveis distribuídas que podem ser armazenadas em memória ou disco dentro de um cluster de servidores. RDDs são resilientes pois possuem a receita para a sua reconstrução em caso de falhas. Existem dois tipos de operações dos RDDs, ações e transformações. As transformações executadas nos RDDs são "lazy", isto é, as transformações não são executadas no momento da execução da instrução de código, mas sim no momento que é executada uma ação. O Apache Spark guarda a receita para as transformações e espera até uma ação para a execução das transformações anteriores dependentes.
Dataframe
Assim como RDDs, um DataFrame é uma coleção imutável de dados distribuídos, mas os DataFrames também possuem uma estrutura de colunas nomeadas como uma tabela de um banco de dados relacional. Com os Dataframes é possível criar uma abstração de alto nível para manipular e transformar os dados. É possível usar uma linguagem própria de manipulação em uma das linguagens compatíveis ou até mesmo SQL.
Dataset
Dataset foi introduzido na versão 1.6 do Spark e a partir da versão 2.0 as APIs de Dataframe e Dataset se uniram. Dataset tem algumas vantagens de performance em relação ao Dataframe principalmente porque tem uma API de type-safe que guarda os tipos das colunas dos dados durante o processo de build.
MLlib
MLlib é a biblioteca de ML do Apache Spark que tem a implementação de alguns algoritmos de ML para processamento em paralelo. Com o processamento paralelo do Spark e a MLlib é possível ter escalabilidade nos treinamentos e inferências dos modelos.
ML Pipelines
ML Pipelines ajuda a organizar e processar as tarefas de pré-processamento, extração de variáveis, inferência e validação e todas as fases de pipeline de ML.
GraphX
GraphX é um componente do Apache Spark para processamento paralelo de grafos, ele implementa uma abstração de grafos em cima dos RDDs.
Spark Streaming
Spark Streaming habilita o processamento de dados real-time com integração com fontes como Apache Kafka e outros. A abstração DStream (Discretized Stream), que foi construída a partir dos RDDs, representa um stream de dados divididos em pequenos lotes e permite que os dados processados sejam carregados em bancos de dados, filesystems e dashboards.
9.2.2 Arquitetura
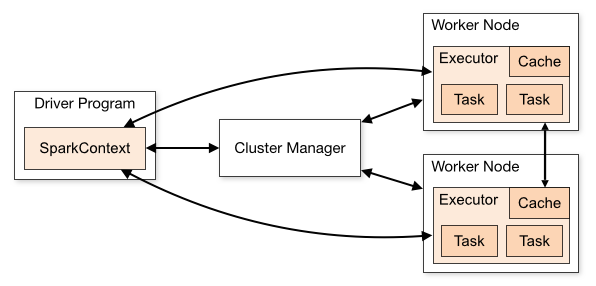
Driver Program: Executa o SparkContext que é responsável por negociar o recurso com o gerenciador de cluster e orquestra a execução dos executores nos worker nodes disponibilizados.
Executors: Responsáveis pela execução das tasks e gestão do cache e disco.
Cluster Manager: Responsável pela gestão do recurso do cluster. Apache Spark é compatível com Yarn, Mesos, Standalone mode e Kubernetes.
9.2.3 Primeiros passos com Apache Spark
A seguir vamos preparar o ambiente Docker para executarmos nossos testes. Crie uma pasta serving-batch/spark para começar a trabalhar com os arquivos do Spark. A imagem base para execução do Apache Spark é python:3.10.11-slim.
Para criar nosso ambiente com Apache Spark vamos utilizar os binários oficiais da Apache.
A imagem do python não tem o java instalado. O trecho a seguir instala os binários do openjdk, instala dependências do SO e faz atualização das ferramentas pip, wheel e setuptools.
Para instalar as dependências de Python vamos utilizar o requirements.txt:
Definir as variáveis de ambiente para executarmos o Pyspark com o Jupyter como driver:
Setup das configurações padrões do Apache Spark:
Definição do entrypoint e diretório de trabalho:
No nosso arquivo de requirements.txt vamos colocar as mesmas dependências para o treinamento do modelo de categoria de modelos e também o pyarrow para usarmos UDFs pandas com Spark e o sparksql-magic para facilitar os comandos de Spark SQL.
Para facilitar as configurações do Spark é comum alterarmos o spark-defaults.conf. Neste caso vamos usar somente para definir o interpretador Python para PySpark, mas podemos alterar qualquer configuração do spark:
Como já aprendemos nos capítulos anteriores vamos criar o docker-compose.yaml para facilitar a execução e build: Vamos configurar volumes locais para acessar os notebooks, os dados e modelos.
Agora com o docker compose pronto podemos subir a instância do spark e acessar o Jupyter na porta 8888 local.
O Apache Spark inicia uma WebUI na porta 4040 para acompanhamento do processamento. Esta WebUI é iniciada somente quando é gerado o Driver para processamento. Para verificarmos vamos criar um kernel no Jupyter e iniciar a sessão do Spark. Copie o seguinte trecho para o notebook:
Verifique que depois da inicialização da sessão do Spark conseguimos acessar a WebUI.
Agora com nosso ambiente pronto vamos entender as operações principais do Apache Spark. Como vimos na seção de conceitos podemos executar ações e transformações nos RDDs e as transformações são "lazy". Vamos comprovar isso na prática. Antes de carregar o CSV copie o arquivo produtos.csv para a pasta ./data. A API de Dataset e Dataframe do Spark é parecida com a do pandas, o trecho de código a seguir carrega um arquivo CSV, o mesmo que usamos nos módulos anteriores:
Verifique que depois da execução do código podemos ver na WebUI a criação de um Job para carregar o CSV. Agora vamos começar a criar as transformações.
Criação de uma nova coluna do resultado da junção de um prefixo e a descrição:
Repare que não foi gerado nenhum Job para processamento na WebUI.
Vamos agora o count por categoria:
Repare que ainda não foi gerado nenhum Job para processamento na WebUI.
Agora vamos imprimir o resultado:
Repare que agora foi gerado um Job na WebUI para imprimir os resultados no notebook. Agora vimos na prática o conceito de "Lazy evaluation" do Spark. Explore a documentação oficial da WebUI para mais detalhes.
O Apache Spark também possibilita a execução de SQL com a API do Spark SQL. O Spark SQL pode ser integrado com catálogos de dados externos como o Hive Metastore, mas para fins didáticos vamos explorar o catálogo local do Spark.
Por padrão o Spark cria um catálogo local, veja que o resultado do comando "show tables":
Para facilitar a execução dos comandos SQL do Spark é possível usar os Magic commands do Jupyter, como usamos a integração nativa entre Jupyter e Pyspark, temos o pacote sparksql-magic. Para habilitar o magic execute os seguintes comandos no notebook:
Agora podemos executar comandos para listar as tabelas com o magic do Jupyter:
Vamos criar uma view temporária para emular uma tabela no nosso catálogo global. Este comando cria uma view temporária para nosso dataframe da transformação 2:
Agora se listarmos as tabelas novamente vamos verificar que existe uma tabela no nosso catálogo global.
Agora vamos consultar a tabela com SQL:
Explore comandos SQL seguindo a sintaxe da documentação oficial.
9.2.4 Portando a inferência do modelo para Spark
Agora que já preparamos nosso ambiente e passamos pelos comandos básicos do Apache Spark vamos criar um processo para executar a inferência da categorização de produtos. Lembrando que a inferência com o Apache Spark é realmente necessária quando estamos lidando com um volume grande de dados, para fins didáticos vamos usar o mesmo CSV de produtos usado nos capítulos anteriores. Para executar a inferência vamos criar uma UDF pandas para Apache Spark.
Vamos iniciar a conversão do código para a inferência, para isso primeiramente vamos gerar um DataFrame para teste:
Este dataframe de teste tem um id, e a descrição dos produtos. Podemos listar o dataframe convertendo-o para pandas:
Como vamos usar o mesmo modelo é necessário gerar o joblib, da mesma forma que foi feito nos capítulos anteriores.
Agora vamos gerar a UDF pandas para executar a predição do modelo: Antes de executar os trechos a seguir, faça o treinamento com o notebook classificador-produtos.ipynb e copie o arquivo joblib no diretório ./model.
O primeiro comando para criar a UDF é disponibilizar o objeto serializado do modelo para todos os workers. Lembre que o Spark é executado de forma distribuída em produção, por isso é necessário que todos os executores tenham acesso ao modelo. O Spark possibilita a criação de UDF (User Defined Functions), para a inferência das categorias vamos usar uma UDF pandas para Apache Spark. Para criar a UDF usamos o decorator @pandas_udf com o parâmetro "string" para definir o tipo do resultado da UDF. A declaração da função deve usar os hints de tipos do Python.
Agora com a UDF pronta vamos executar a predição:
Repare como resultado temos uma coluna nova "predict" com o resultado da predição. Executamos o cenário de teste, mas como funciona em um cenário produtivo? Vamos emular um cenário produtivo que consultamos um CSV de entrada, executamos a inferência para todos os registros e por fim devolvemos os dados para o storage com as inferências prontas. Para fins didáticos vamos usar o mesmo CSV de produtos:
Vamos criar uma chave para cada descrição para simular um ID. Agora com o DataFrame criado vamos executar o mesmo código de predição usado para o teste:
Agora vamos gravar o resultado no disco:
Repare que CSV foi gerado com as predições da categoria do produto. Nesta seção aprendemos a executar uma inferência de modelo utilizando o paralelismo do Apache Spark através de UDFs pandas.
Atualizado